|
|
|
|
|
|
|
|
|
Dataset
| Instructions generated by speaker model ("original_instr"), as well as human annotations on word-level hallucination ("labeled_instr"). |
| Each word-level hallucination label corresponds to the preceding word, e.g. "Walk through (1)", the word "through" is labeled as 1. Non-hallucination label: (1); Hallucination labels: (0), (-1). |
|
|
| We investigate the problem of generating instructions to guide humans to navigate in simulated residential environments. A major issue with current models is hallucination: they generate references to actions or objects that are inconsistent with what a human follower would perform or encounter along the described path. We develop a model that detects these hallucinated references by adopting a model pre-trained on a large corpus of image-text pairs, and fine-tuning it with a contrastive loss that separates correct instructions from instructions containing synthesized hallucinations. Our final model outperforms several baselines, including using word probability estimated by the instruction-generation model, and supervised models based on LSTM and Transformer. |
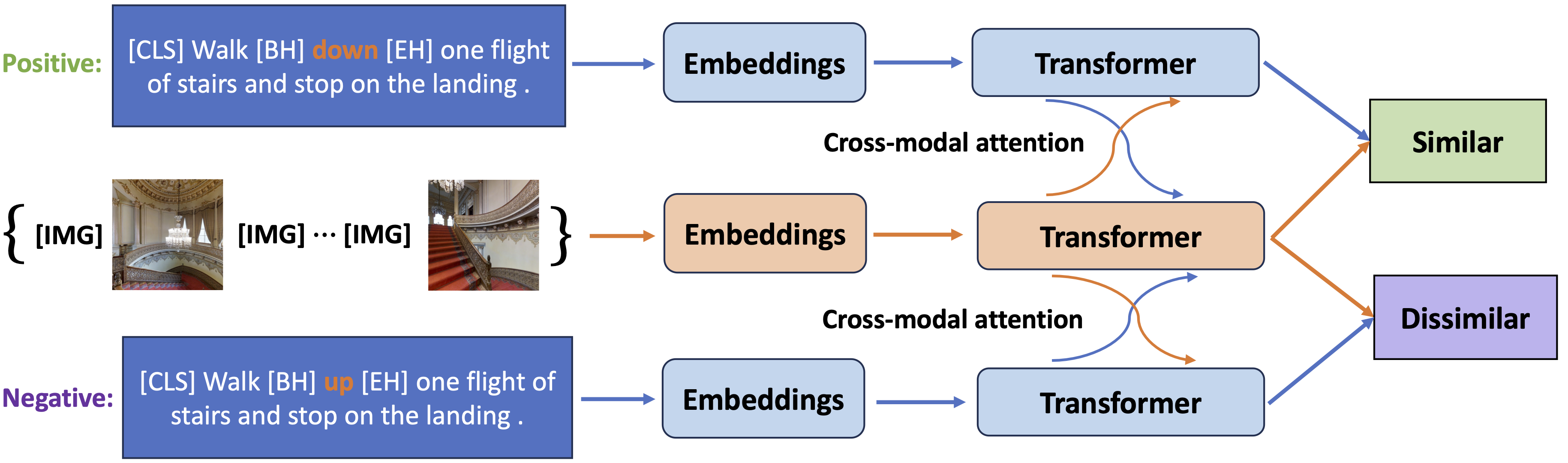
|
| Our hallucination detection model, which takes as input an instruction with a target word and determines whether it should be replaced or removed to be consistent with a visual trajectory. To build this model, we fine-tune pre-trained Airbert (Guhur et al., 2021) with a contrastive learning objective. |
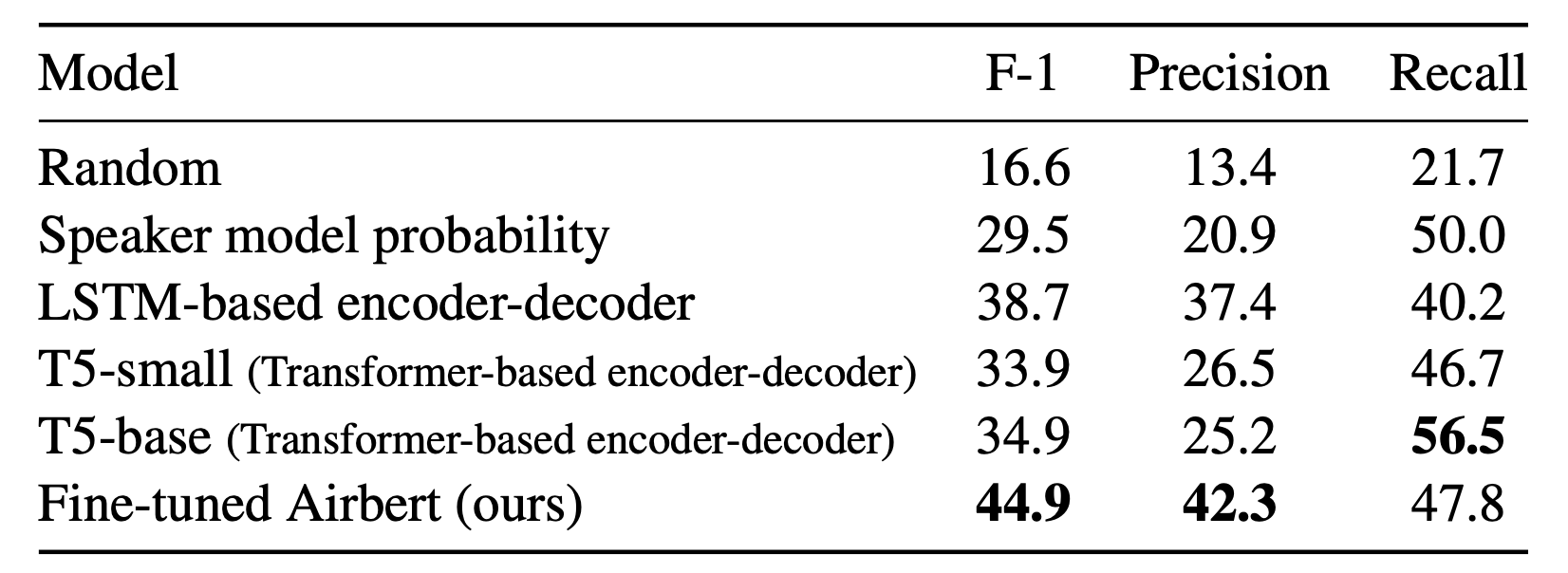
|
| Our model detects grounded word-level hallucinations better than strong baselines. |
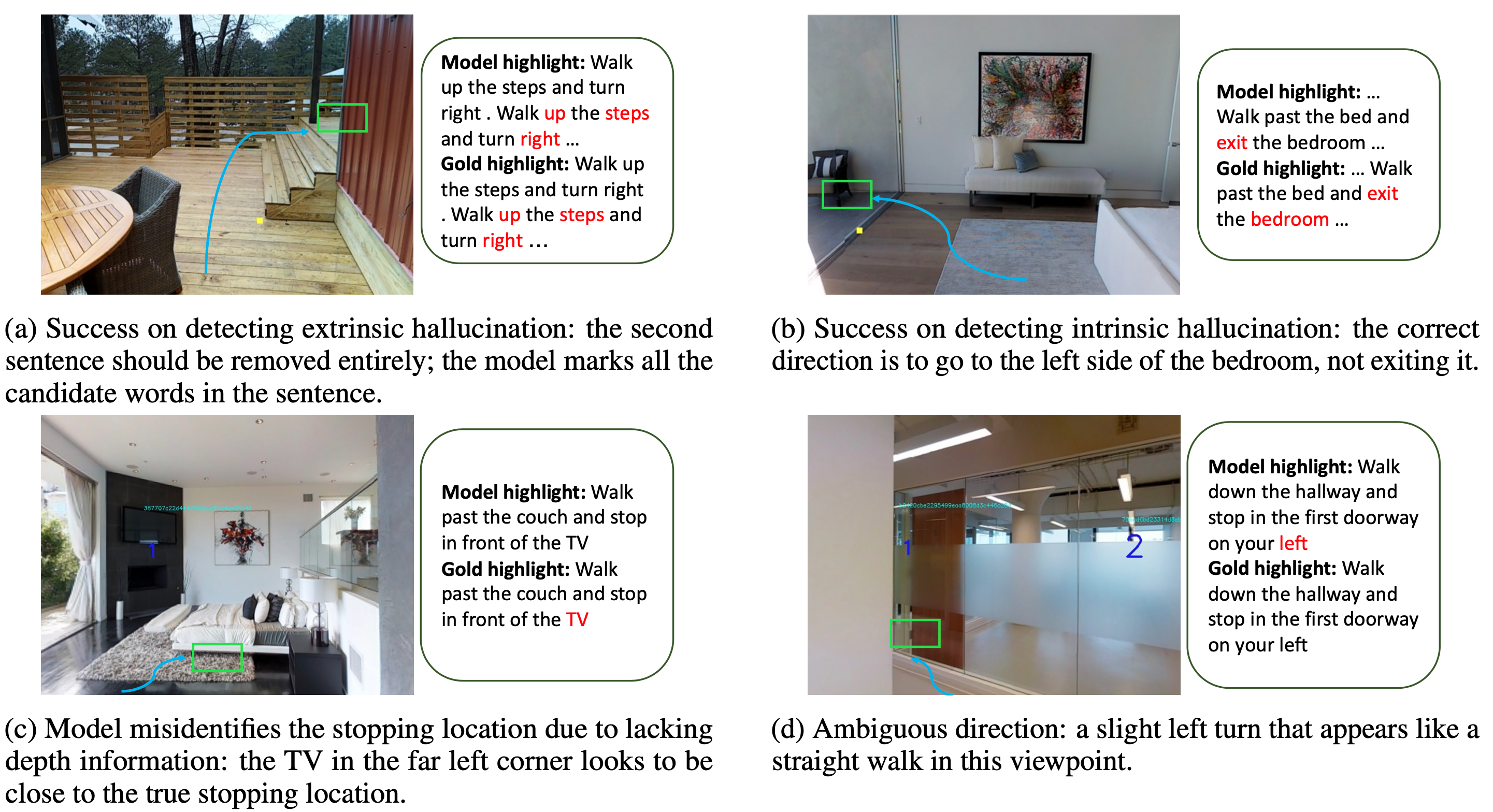
|
| Some successful and failure cases of the fine-tuned Airbert model. The blue arrow indicates the described path, and the green represents the next location. |
Acknowledgements |