|
Recent work studies the cognitive capabilities of language models through psychological tests designed for humans.
While these studies are helpful for understanding the general capabilities of these models, there is no guarantee that a model possessing sufficient capabilities to pass those tests would actually use those capabilities in performing real-life tasks.
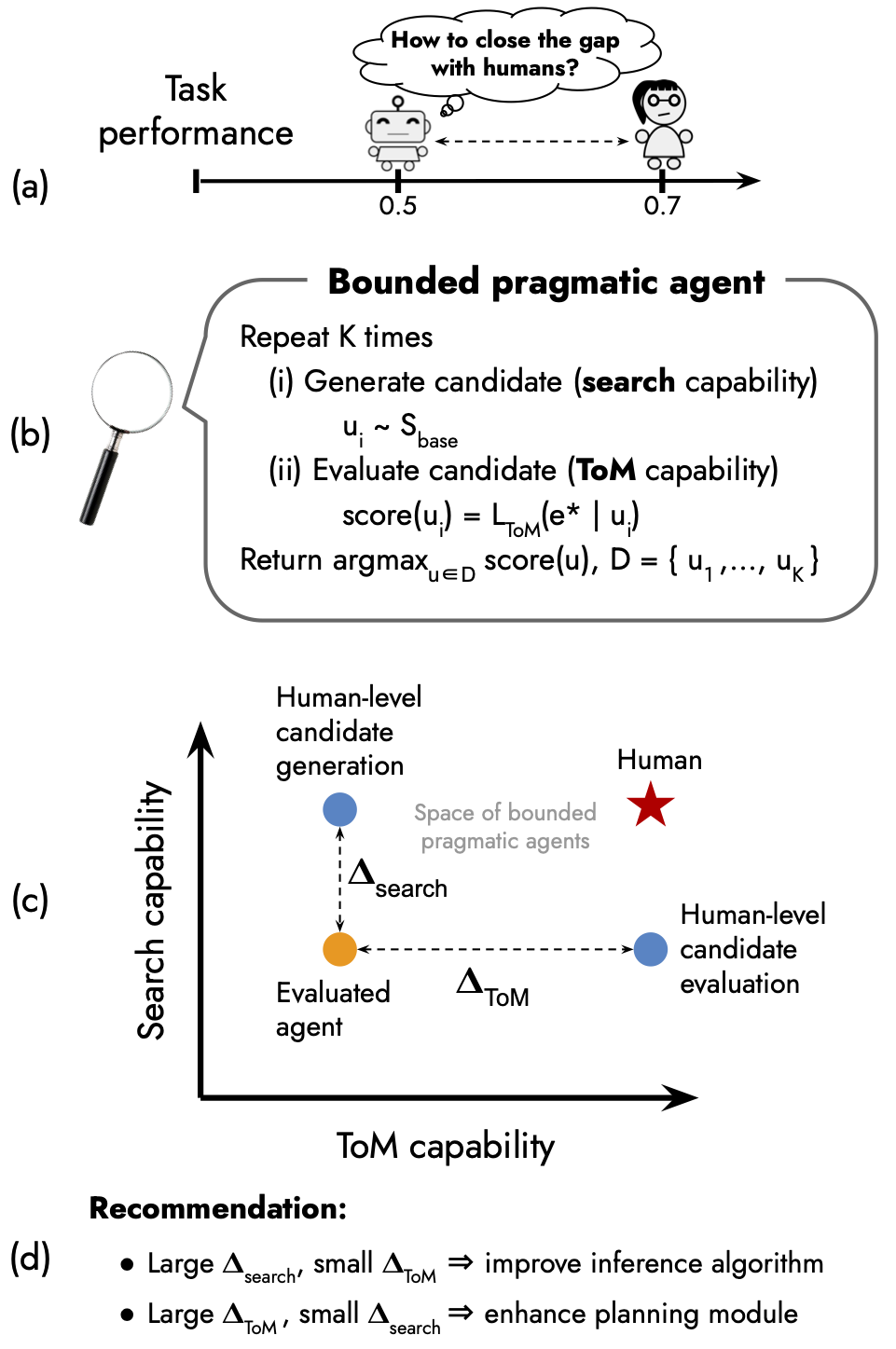
In this work, we formulate task-oriented cognitive capabilities, which are human-like cognitive capabilities that language models leverage to perform tasks.
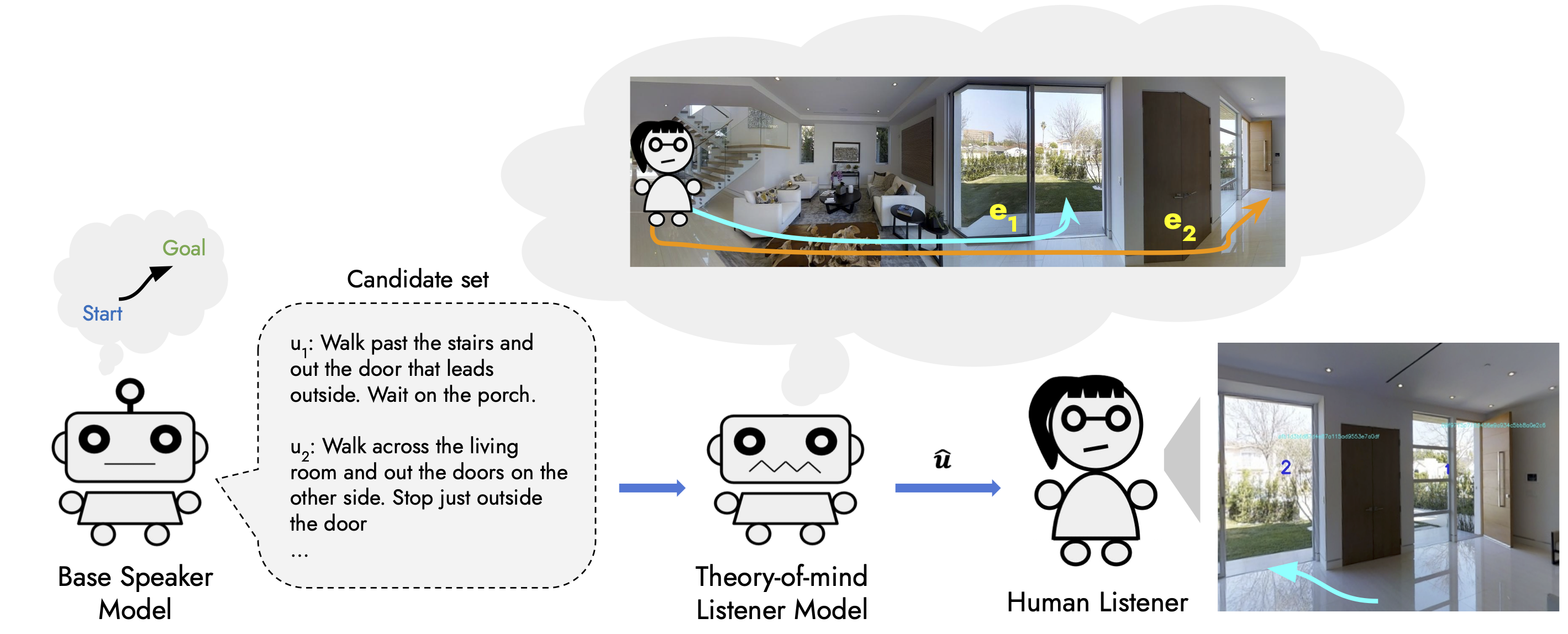
These capabilities are (i) the ability to quickly generate good candidate utterances (the search capability) (ii) the ability to predict how a listener interprets those utterances and choose the most appropriate one (the pragmatic capability).
We design an evaluation scheme for comparing these capabilities of a language model with those of a human.
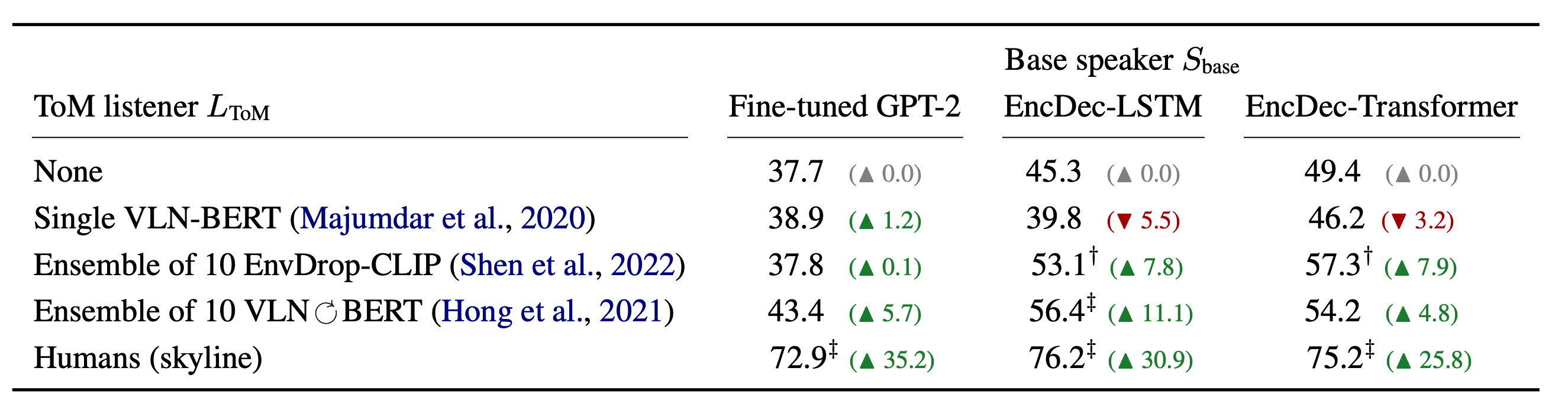
Applying this scheme to examine various models in a navigation instruction generation problem, we find that their pragmatic capability is severely lacking.
This insight leads us to augment them with better models of the listener and obtain a significant boost of 11\% in success rate in guiding real humans.
Our work advocates for having a principled procedure for aligning language models with humans that involves (i) formulating task-oriented capabilities, (ii) devising a method to quantify their deficiency, and (iii) iteratively improving them.
|